深度卷积神经网络中的升采样
语义分割中的FCN、U-Net,目标检测中的FPN、DSSD、YOLOV3等模型为了增强模型效果,都会通过hour glass结构来融合低层和高层的信息,这样融合后的特征既具有高层特征的抽象语意信息,又具有低层特征的细节信息。而低层特征feature map比高层特征feature map大,为了融合,需要将高层特征feature map放大到跟低层特征feature map一样大,放大feature map的过程也就是升采样(upsample)过程,如下图所示。升采样具体实现有插值方式和deconv方式。
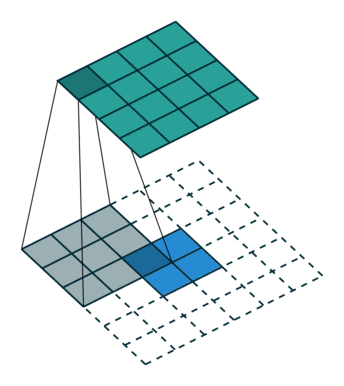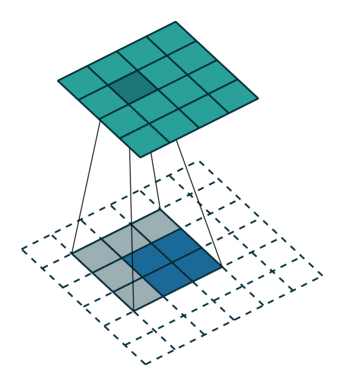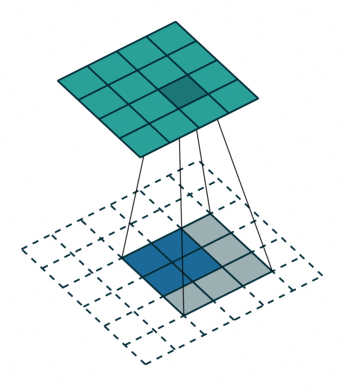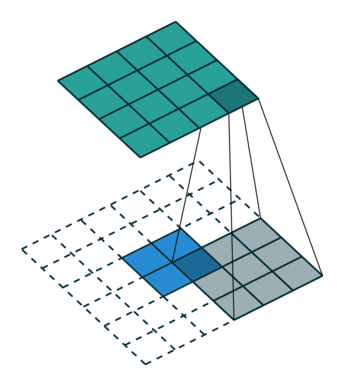
一、插值
插值常用的方式有nearest interpolation、bilinear interpolation、bicubic interpolation。
1、nearest interpolation
将离待插值最近的已知值赋值给待插值。
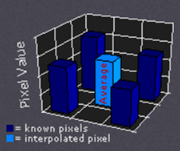
2、bilinear interpolation
根据离待插值最近的 \(2 \times 2\) 个已知值来计算待插值,每个已知值的权重由距离待插值距离决定,距离越近权重越大。示意图和计算公式如下所示。

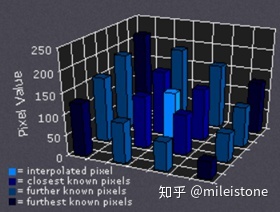
3、bicubic interpolation
根据离待插值最近的 \(4 \times 4\) 个已知值来计算待插值,每个已知值的权重由距离待插值距离决定,距离越近权重越大。示意图如下所示。
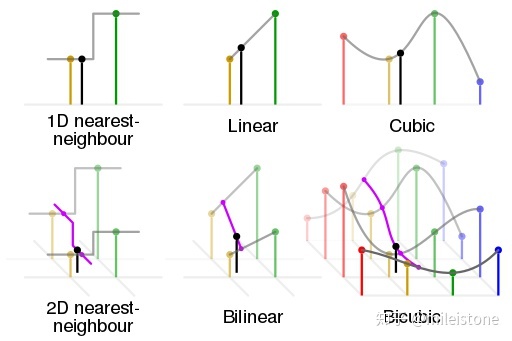
4、各种插值方式的区别与联系
从nearest interpolation、bilinear interpolation到bicubic interpolation,插值所利用的信息越来越多,feature map越来越平滑,但是同时计算量也越来越大,nearest interpolation、bilinear interpolation、bicubic interpolation的区别与联系可见下图示意,其中黑色的点为预测值,其他彩色点为周围已知值,用来计算预测值。
二、deconv
自从步入深度学习时代,我们越来越追求end2end,那么升采样能不能不用人为定义的权重,而让模型自己学习呢?答案是显然的,deconv就是解决方案之一。
1、stride=1
等价于stride=1的conv,只是padding方式不同,不能起到升采样的作用。以一维的数据为例,示意图如下,中间步骤是将卷积转换为矩阵乘法的过程。

2、stride > 1
能起到升采样的作用,一般用到的deconv,stride都大于1。以一维的数据为例,示意图如下,中间步骤是将卷积转换为矩阵乘法的过程。

3、名字
deconvolution也叫transposed convolution,upconvolution等等。其中deconvolution这个名字有点歧义性,容易带来困惑,transposed convolution比较容易理解。容易验证1和2中convolution和deconvolution中的权重矩阵互为转置。
三、deconv和插值的区别与联系
deconv和插值,都是通过周围像素点来预测空白像素点的值,区别在于一个权重由人为预先定义的公式计算,一个通过数据驱动来学习。