深度学习高效网络设计
这一年来一直在做高效网络设计的工作,2018年即将结束,是时候写一篇关于高效网络设计的总结。
首先看看当前业界几个最负盛名的高效网络简介:
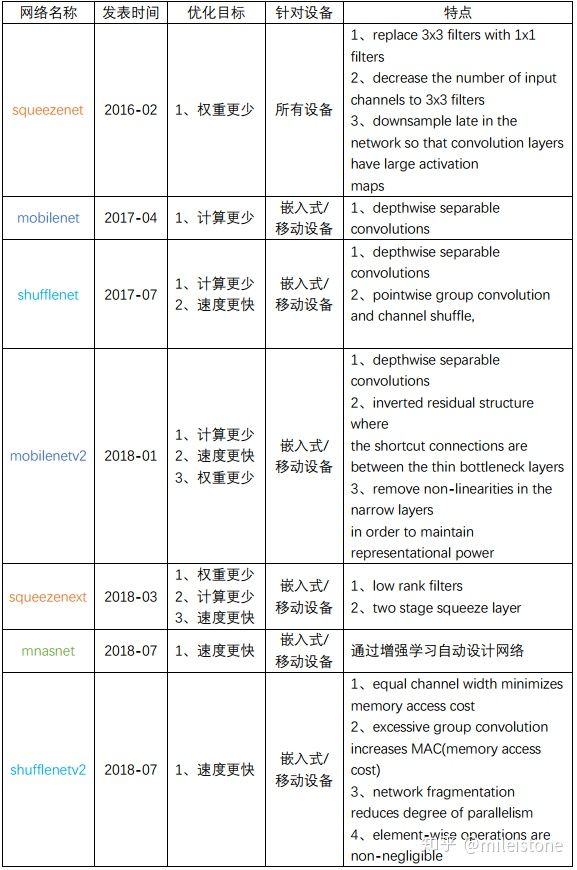
以上网络的目标主要有三个:权重少、计算少、速度快。这三者之间不存在着严格的相关关系,它们是三个独立的目标。即权重少不代表计算量少;计算量少不代表速度快。
高效网络高效的含义比较模糊,有的文章认为计算量小就是高效,有的文章认为速度快即高效。本篇总结主要从速度快入手。
速度快慢与计算量、结构是否利于并行、内存读取、运算硬件平台、具体软件实现等等都有关系,所以没有比较公允的衡量方式,一般比较好的衡量方式就是直接测速度。
从上述高效网络文章可以看出,高效网络的设计思路有如下几条:
1、depthwise separable convolutions
2、low rank filter
3、pointwise group convolution
4、避免网络分支太多,或者group太多
5、减少element wise的操作
既然已经有这么多高效网络,为什么要我们还要重新设计网络?
因为网络与任务相关,例如分类还是检测,分类是多少类,难度如何;检测是多类别检测还是单类别检测,如果是单类别,这个类别的物体有什么特性,例如人脸检测和人体检测的网络设计思路就大相径庭。我们工作中面临的任务大部分与论文里提出网络针对的任务不同,如果我们直接将论文里提出的模型拿过来用,而不加以改进,这个网络很可能不够好,例如准确率还有优化空间、或者速度还有优化空间。
高效网络和复杂网络设计的区别较大。如:
1、残差结构,仅仅是一个加的操作,这个操作在复杂网络里所耗的时间可以忽略不计,但是在高效网络里,它却成为了不可忽视的因素[shufflenetv2];
2、bottleneck,在复杂网络里,认为bottleneck可以减少计算量,但是在高效网络里,bottleneck却可能成为耗时的瓶颈
[shufflenet]We notice that state-of-the-art basic architectures such as Xception and ResNeXt become less efficient in extremely small networks because of the costly dense 1 × 1 convolutions. We propose using pointwise group convolutions to reduce computation complexity of 1 × 1 convolutions [shufflenet]for each residual unit in ResNeXt the pointwise convolutions occupy 93.4% multiplication-adds (cardinality = 32) 3、大kernel size filter。在复杂网络里,我们越来越少用kernel size大的filter,例如5x5、7x7,我们认为用多层3x3就能达到大kernel size filter的感受野,例如两层3x3可以达到一层5x5的感受野,3层3x3可以达到一层7x7的感受野,同时计算量更小,由于网络更深,非线性也更优。但是在高效网络里,可能事情有些不同。
例如FaceBoxes提出的RDCL模块,用四层网络将feature map降为1/32。feature map大的部分非常耗时,不宜恋战,为了加速,需要在网络前端尽快将feature map的大小降下来,这个时候大kernel size filter有了用武之地,RDCL里面用到了7x7和5x5的大kernel。
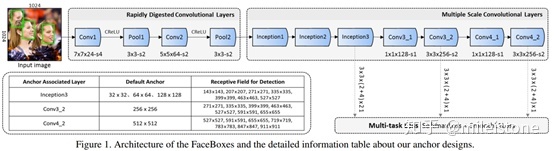
4、任务相关性。复杂网络因为表达能力够强,所以对任务不是很敏感;高效网络为了达到高效,需要充分利用任务的特点,针对该特点将与之无关的计算全部砍掉,这是高效网络的优点。然而世间没有免费的午餐,这个优点会带来缺点,因为高效网络与任务强耦合,换一个任务,网络的效果可能就不太好。例如将FaceBoxes这个网络backbone用来检测人体,效果会打一定折扣,因为人体数据的分布与人脸差异较大。
如何重新设计网络?
我将设计网络分为了五个层次:
0、入门级,直接整体替换backbone
例如将VGG16换为mobilenet。
1、初级,减channel,砍block
即成比例地降低一个经典网络的channel,例如channel数降低为之前的1/2;或者stage的block重复数减小,例如将某个stage的block重复数从8减小为6。
2、中级,替换block
比如mobilenetv2出来了之后,整体将之前模型的block替换为mobilenetv2的block;或者shufflenetv2出来之后,整体将之前模型的block替换为shufflenetv2的结构。
3、高级,从头开始设计,集众家之所长
即理解业界各个经典模型背后的motivation以及解决思路,不再拘泥于生搬硬套。将各个经典模型背后的设计思路吃透,了然于胸,下笔如有神。
4、科学家,设计出新的模块,为业界添砖加瓦,例如depthwise separable convolutions,shuffle channel等等。
网络设计的未来
从NASNet和MnasNet的相继推出,以及我自己设计网络的实践经历来看,我认为最终网络设计会完全被机器替代。
首先,我自己设计网络的过程,大概就是看各种网络结构的论文,然后把这些论文里的设计思路用到网络设计中,思路验证对了之后,再根据这个思路不断改超参,搜索得到一个该思路下的局部最优模型。这个过程其实跟NAS的过程一模一样,即给定一些经典设计思路,和网络目标,最后组合这些网络设计思路得到最优模型。

如果有公司能够提供比算法工程师更便宜的nas服务,我想大部分从事网络设计的算法工程师就可以下岗了,就跟当年工业革命,纺纱机出现了之后,纺织工人最后要么被裁,要么自谋出路。硬件只会越来越便宜,而算法工程师的待遇不可能一直降低,所以我想总有一天网络设计会被机器取代,就如同AlphaGo大败李世石和柯洁一样。最后nas应该都不需要输入网络设计思路,它自己就能找到最优的网络设计思路,就像AlphaZero都不需要学习人类棋谱,自我博弈就可成为围棋大师。
NAS服务是一群这个领域内最厉害科学家所设计的服务,nas所设计出来的模型以后必然会比大部分算法工程师好,如果nas服务又好又便宜,那么大部分公司应该都不需要雇佣算法工程师。