重新认识图像分类模型
Network In Network是图像分类模型中第一个使用GAP替换FC+dropout的方法,从此之后的分类模型全都开始使用GAP方案。也就是图1所示的样子。
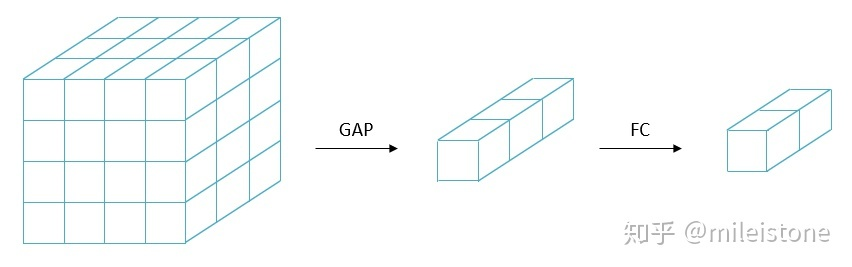
将图1中的GAP去掉,同时将FC层转换为1*1的conv(权重从FC里直接拷贝过来),得到图2所示的样子。
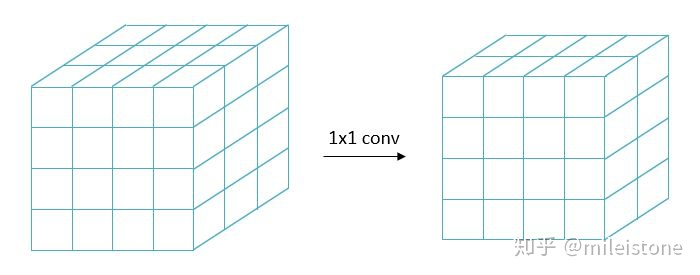
对于一个通过图1方式来训练得到的分类器,可以转换为图2的形式。通过图2方式,分类器变成了语义分割模型,通过该模型,我们不仅可以对一张图像进行分类(即,这张图像是否包含什么物体),还能可以该定位出该图像中的物体(即,该物体在图像哪个地方),这就是CAM的原理。
按照我们的直观感受,图1方式的GAP应该会让分类器丢掉位置信息,而且分类器的label也不包含位置信息。为什么图1方式训练的模型,转换为图2方式的时候,却能获取位置信息呢?
答案藏在图1和图2中。
刚刚的情况是图1方式训练,预测的时候转换成图2方式。如果我们直接通过图2方式进行训练,预测的时候依然用图2方式呢?
这个时候,分类任务就类似语义分割任务,举个例子:训练集中有一张图像A,类别是猫,1*1 conv输出的feature map大小为7*7,每个cell的label都是猫。每个cell对应到原图中一个patch(通过感受野可以对回去),图1方式训练的时候,对全图进行分类;图2方式训练,则是对每个patch进行分类,诶,位置信息有了。
但是这带来了一个新问题,图2方式训练的时候,7*7一共49个patch的label都是猫,实际情况是,整张图中不完全都是猫,往往只有一部分是猫,其他部分是背景。
直觉来看似乎有问题——label中有noise。这个时候我们联想到multiple instance learning。
In machine learning, multiple-instance learning (MIL) is a type of supervised learning. Instead of receiving a set of instances which are individually labeled, the learner receives a set of labeled bags, each containing many instances.
In the simple case of multiple-instance binary classification, a bag may be labeled negative if all the instances in it are negative. On the other hand, a bag is labeled positive if there is at least one instance in it which is positive.
From a collection of labeled bags, the learner tries to either (i) induce a concept that will label individual instances correctly or (ii) learn how to label bags without inducing the concept.
图2方式训练的时候,这就是multiple instance learning问题,另外分类任务一般目标物体在全图中占比较高,噪声比例不会太大,学习不会太困难。
如果图1方式和图2方式等价,那么刚刚的问题“为什么图1方式训练的模型,转换为图2方式的时候,却能获取位置信息呢?”就解决了。
遗憾的是图1方式训练和图2方式训练并不等价,但是二者存在较大的内在联系,I conjecture 图1方式训练的模型具备定位能力的原理与图2方式类似。